

BeetSoft offers a range of image annotation services tailored to meet the specific requirements of each client's project. These services include bounding boxes, polygon annotations, keypoint annotation, LiDar, semantic segmentation, and image classification. The team at BeetSoft collaborates closely with clients to ensure the quality and efficiency of the annotation process, providing the best cost-quality ratio through iterative improvements. To streamline the process, it is advisable to run a sample batch to clarify instructions, address edge cases, and estimate task durations before proceeding with full-scale annotation.
High-quality image annotation plays a crucial role in generating ground truth datasets essential for optimal machine learning performance. Various industries, including autonomous technology & transportation, medical AI, commerce, geospatial, finance, government, and others, benefit from deep learning applications enabled by accurate image annotation.
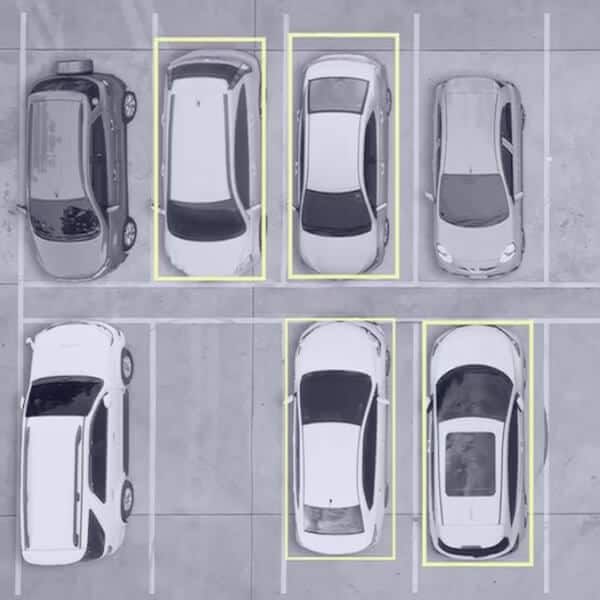
BOUNDING BOXES
Rectangular box annotation, often referred to as bounding box annotation, stands out as the most widely adopted method in computer vision. BeetSoft's computer vision specialists leverage this technique to delineate objects and facilitate data training. By annotating images with rectangular boxes, algorithms gain the ability to recognize and localize objects throughout the machine learning journey. The straightforwardness of bounding boxes is precisely what makes them so versatile, rendering this annotation method suitable for diverse applications.

POLYGON ANNOTATION
Specialized annotators mark points on every vertex of the object of interest. Polygon annotation ensures precise delineation of all edges of the object, accommodating various shapes. This enables computer vision and other AI models to detect and interact with objects accurately. Particularly valuable in computer vision, this technique empowers annotators to identify irregular shapes, equipping computers with the ability to detect and respond to them effectively.

SEMANTIC SEGMENTATION
The BeetSoft team initially segments images into their constituent parts before proceeding with annotation. BeetSoft's computer vision specialists excel at identifying specific objects within images down to the pixel level. Through meticulous semantic segmentation, data can be structured into various formats to suit the needs of AI models across diverse applications.

LIDAR ANNOTATION
BeetSoft's team meticulously label images and videos captured from multi-sensor cameras, ensuring comprehensive 360-degree visibility. This effort aims to construct precise and top-tier ground truth datasets vital for training computer vision models, particularly those utilized in autonomous vehicle technology.
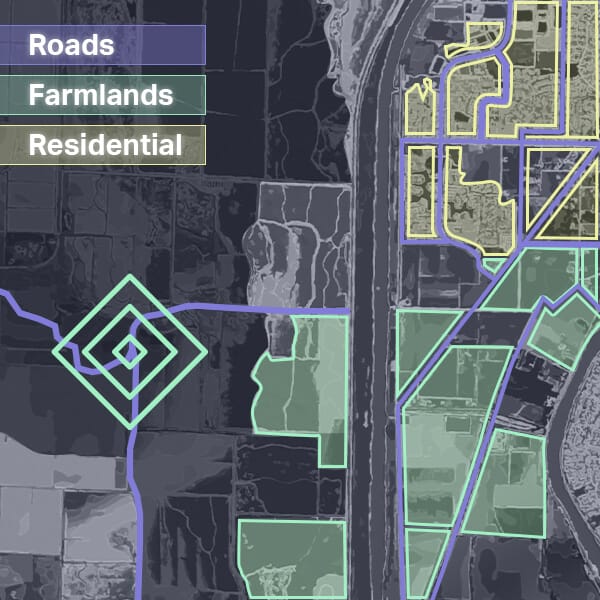
IMAGE CLASSIFICATION
BeetSoft's annotators proficiently classify images or objects within images using customized multi-level taxonomies, covering diverse categories such as land use, crops, residential property features, and more. Through expert image classification, raw image data is transformed into valuable insights for AI and ML models, enhancing their accuracy and performance.

3D CUBOID ANNOTATION
BeetSoft annotators leverage cuboids to create training datasets, enabling machine learning models to grasp the depth of objects accurately. Through expert data labeling, BeetSoft develops top-tier training datasets tailored for computer vision models, enhancing their ability to detect object dimensions and obstacles effectively. By strategically placing anchor points at the edges of items and connecting them with lines, a 3D representation of the object is generated, facilitating comprehensive understanding.

KEYPOINT ANNOTATION
BeetSoft teams utilize keypoint annotation to delineate objects and variations in shape by connecting discrete points across objects. This annotation method is particularly adept at detecting body features, including facial expressions and emotions. Keypoint annotation finds widespread application in facial recognition and other related tasks where precise identification of key features is crucial.

POLYLINE ANNOTATION
BeetSoft experts craft training datasets employing polyline annotation, instructing machine learning models to recognize physical boundaries for navigation. This annotation method is widely employed in various applications, notably in training autonomous vehicles to understand road boundaries and operate within defined spaces effectively.
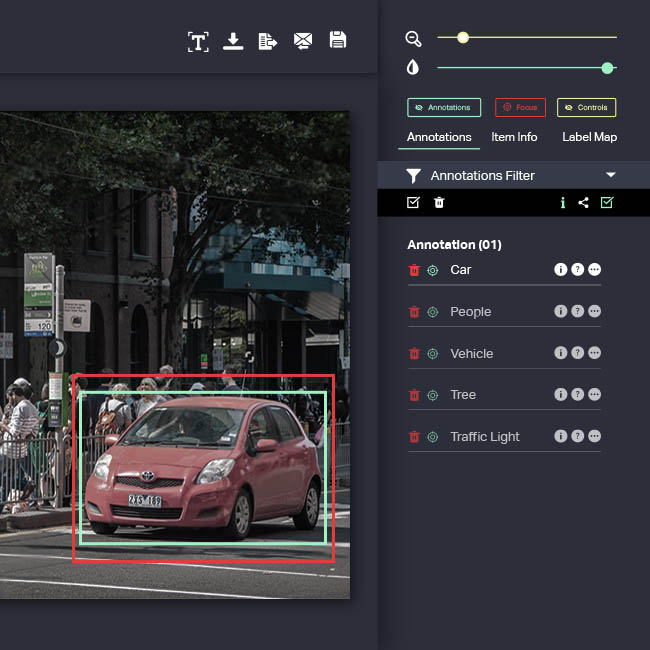
RAPID ANNOTATION
BeetSoft's image annotation platform leverages image interpolation to quickly annotate a variety of file formats, including JPG, PNG, and even CSV. BeetSoft's annotation experts excel in creating high-quality video training datasets efficiently, catering to any AI or ML project requirements. Empower your data science team with the expert service they require to transition their project from conception to production.

Autonomous Technology & Transportation
Image annotation services play a pivotal role in advancing autonomous technology by annotating images depicting a car's surroundings.
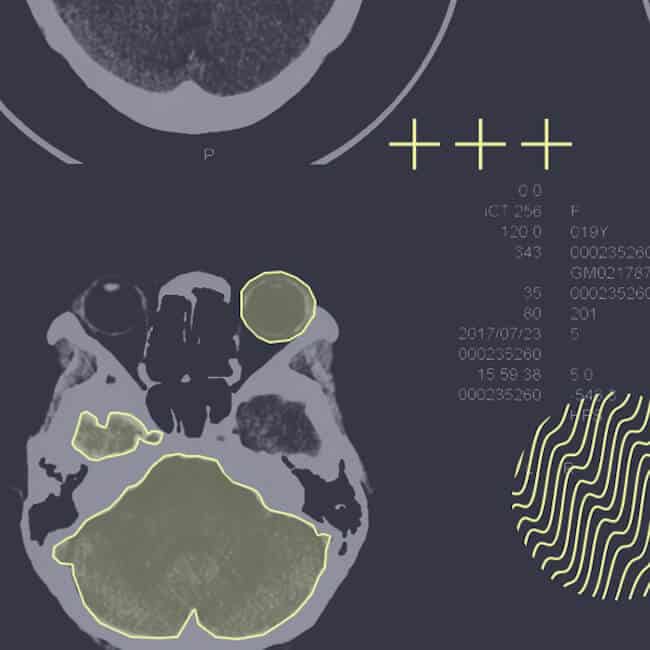
Medical AI
Medical image annotation involves labeling medical imaging data to aid in disease diagnosis and anomaly detection.

Commerce
In e-commerce, image annotation involves categorizing product content based on multiple attributes, enhancing search relevance and improving the online shopping experience for customers.
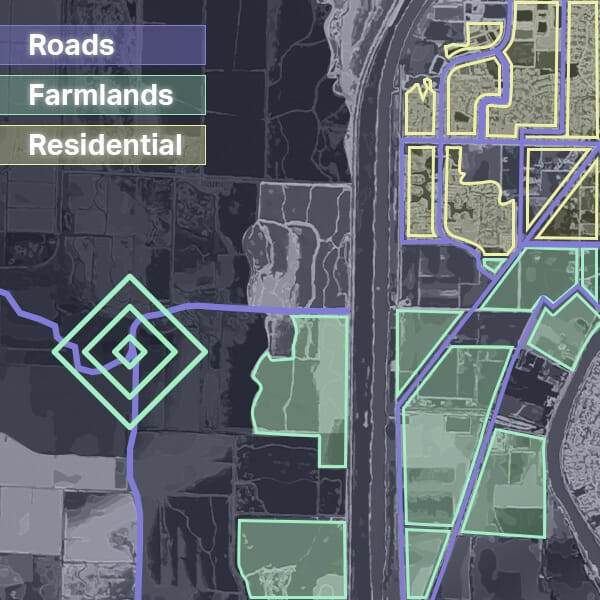
Geospatial Technology
Image annotation tasks encompass extracting valuable insights from satellite, aerial, and drone imagery, fueling applications across various sectors such as energy, agriculture, logistics, security, and mapping.
Finance & Insurance Tech
Image annotation specialists extract and organize pertinent information from extensive collections of unstructured visual data, facilitating the automation of manual tasks and optimization of operations.

Government
In the public sector, image annotation experts provide solutions for handling sensitive data that necessitates processing at various governmental levels, including federal, state, and local authorities.

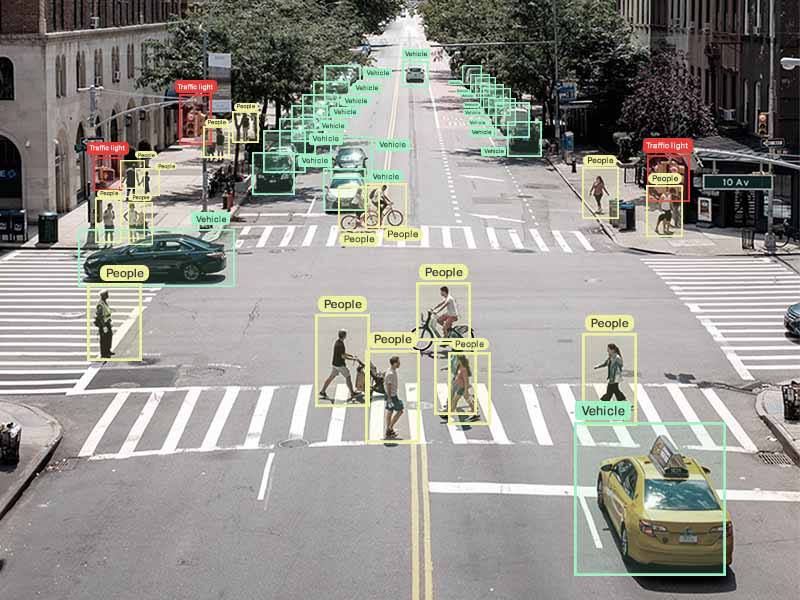





-
0
IMAGES ANNOTATED
-
0
ACCURACY


GETTING STARTED WITH IMAGE ANNOTATION
The need for speed in high-quality image annotation has never been greater. BeetSoft combines the best predictive and automated annotation technology with world-class data annotation and subject matter experts to deliver the data you need to get to production, fast.